日付;2024/05/26(日)、2025/02/15(土)他の記事でもGSEAを書いたことを記載。
以前、Preranked GSEA(Gene Set Enrichment Analysis)について時々使う必要があるために覚書として記載したが、そいうえば、複数サンプルの場合の一般的なGSEAについては書いたことがなかったためにここで記載しておく。データのフォーマットとか、どの変数に何を入れるとか、いちいち忘れてマニュアルを見る羽目になるので、実行の手順を書いておく。GSEAについては別の記事でも書いているので、もしRNAシークエンスをRを使って解析しており、その一連の流れでGSEAの使い方を知りたい場合は、そちらも参考になると思う。ただし、値段も少し高いし、記事は長いし、GSEAの内容はここほど詳しく書いていないし、ハンズオンじゃないしで、こちらの記事のほうが良いような気もするが。
使用するソフト
使用するソフトはBroad Instituteが保持しているGSEA(https://www.gsea-msigdb.org/gsea/index.jsp)を使用する。ソフト名(GSEA)と解析名(GSEA)が同じなので、ちょっと煩わしい。「GSEAをGSEAにより行った」とかになりかねない。
GSEAを行うためには他にclusterProfiler、fgsea、その他多数があるが、正直、これが一番良いように思う。これはしっかりと裏をとったわけではないが、おそらくこのソフトだけがサンプル間のPermutation testを実装しているように思う。
重要な点はメンテナンスがされていることである。遺伝子セットも更新されているようだ。この手の解析ではClusterProfilerがおそらくエンリッチメント解析で一番使われていると思うが、このライブラリは、ほとんどメンテナンスされていないように見える(気がついたらアップデートされたけど)し、マニュアルもかなり酷く(これは本当にイラッとする)、利点のひとつとしてKEGGのパスウェイでエンリッチメント解析する関数があるのだが、これもサーバーにつながらなかったりするし(Vignetteにあるコードも動かなかったりする)、Pathviewも動かないときがあったりと、機能不全が多く、正直好きではない。
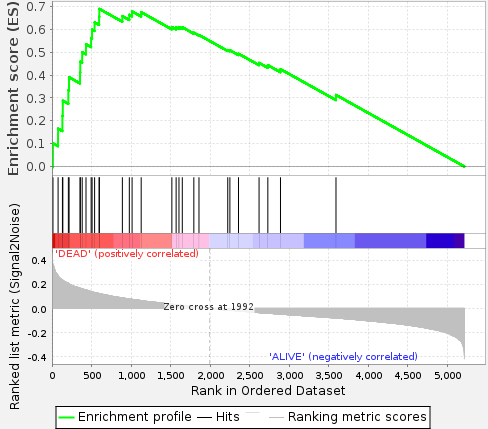
個人的は意見ではあるが、一方のGSEAには欠点もある。それは出てきた出力がわかりにくい点である。ClusterProfilerとかのように、シンプルに遺伝子セットの数に対するエンリッチされてきた遺伝子の数の比を出してくれれば良いものの、Enrichment Scoreだの、Normalized Enrichment Scoreだのを出してくる。一番重要な値をそういう小難しい計算を使って出すのならば、マニュアルにも使った値や計算方法を書いてほしいところである。こういうことがあるから、知っている人ならばclusterProfilerやfgseaに逃げるのである。
というか、ClusterProliferの最大利点ってのはあの綺麗なDotplotがシームレスに書くことが出来ることだろうと思う。しかし、あれ実はggplot2でほぼ同じものを描けるので、そうなってくると一気にclusterProfilerを使う意味がなくなる。他にも色々な図を出力できるが、正直どれも複雑すぎて情報の要約になってない。完全に解析者の自己満足に終わる。
そういうことで、以下に具体的な手順を述べる。